Definitions of Reproducibility¶
The most common definition of reproducibility (and replication) was first noted by Claerbout and Karrenbach in 1992 [CK92] and has been used in computational science literature since then. Another popular definition has been introduced in 2013 by the Association for Computing Machinery (ACM) [IT18], which swapped the meaning of the terms ‘reproducible’ and ‘replicable’ compared to Claerbout and Karrenbach.
The following table contrasts both definitions [HBP+18].
Term |
Claerbout & Karrenbach |
ACM |
|---|---|---|
Reproducible |
Authors provide all the necessary data and the computer codes to run the analysis again, re-creating the results. |
(Different team, different experimental setup.) The measurement can be obtained with stated precision by a different team, a different measuring system, in a different location on multiple trials. For computational experiments, this means that an independent group can obtain the same result using artifacts which they develop completely independently. |
Replicable |
A study that arrives at the same scientific findings as another study, collecting new data (possibly with different methods) and completing new analyses. |
(Different team, same experimental setup.) The measurement can be obtained with stated precision by a different team using the same measurement procedure, the same measuring system, under the same operating conditions, in the same or a different location on multiple trials. For computational experiments, this means that an independent group can obtain the same result using the author’s own artifacts. |
Barba (2018) [Bar18] conducted a detailed literature review on the usage of reproducible/replicable covering several disciplines. Most papers and disciplines use the terminology as defined by Claerbout and Karrenbach, whereas microbiology, immunology and computer science tend to follow the ACM use of reproducibility and replication. In political science and economics literature, both terms are used interchangeably.
In addition to these high level definitions of reproducibility, some authors provide more detailed disctinctions. Victoria Stodden [Sto14], a prominent scholar on this topic, has for example identified the following further distinctions:
Computational reproducibility: When detailed information is provided about code, software, hardware and implementation details.
Empirical reproducibility: When detailed information is provided about non-computational empirical scientific experiments and observations. In practice this is enabled by making data freely available, as well as details of how the data was collected.
Statistical reproducibility: When detailed information is provided, for example, about the choice of statistical tests, model parameters, and threshold values. This mostly relates to pre-registration of study design to prevent p-value hacking and other manipulations.
Table of definitions for reproducibility¶
At The Turing Way we define reproducible research as work that can be independently recreated from the same data and the same code that the original team used. Reproducible is distinct from replicable, robust and generalisable as described in the figure below.
|
|---|
How the Turing Way defines reproducible research |
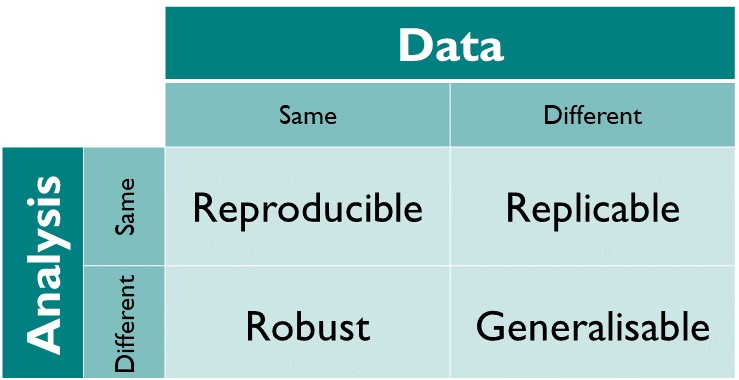
The different dimensions of reproducible research described in the matrix above have the following definitions:
Reproducible: A result is reproducible when the same analysis steps performed on the same dataset consistently produces the same answer.
Replicable: A result is replicable when the same analysis performed on different datasets produces qualitatively similar answers.
Robust: A result is robust when the same dataset is subjected to different analysis workflows to answer the same research question (for example one pipeline written in R and another written in Python) and a qualitatively similar or identical answer is produced. Robust results show that the work is not dependent on the specificities of the programming language chosen to perform the analysis.
Generalisable: Combining replicable and robust findings allow us to form generalisable results. Note that running an analysis on a different software implementation and with a different dataset does not provide generalised results. There will be many more steps to know how well the work applies to all the different aspects of the research question. Generalisation is an important step towards understanding that the result is not dependent on a particular dataset nor a particular version of the analysis pipeline.
More information on these definitions can be found in “Reproducibility vs. Replicability: A Brief History of a Confused Terminology” by Hans E. Plesser [Ple18].
Reproducible but not open¶
The Turing Way recognises that some research will use sensitive data that cannot be shared and this handbook will provide guides on how your research can be reproducible without all parts necessarily being open.